Mise à jour de mes paquets Anki de japonais: +123 mots et +14 kanjis, et toujours des corrections et des exemples d’utilisation de mots.
Mise à jour de mes paquets Anki de japonais (juin 2015)
Laisser un commentaire

Mise à jour de mes paquets Anki de japonais: +123 mots et +14 kanjis, et toujours des corrections et des exemples d’utilisation de mots.
I upgraded from Kubuntu from 14.04 to 15.04 (in order to get MTP support for my phone), and unfortunately it is really beta quality.
I also noticed that the « open file » dialog boxes (in particular the one for choosing a wallpaper image) does not display preview images larger than 5 Mo (default limit). If you want to choose a photo taken with your DSLR it can be annoying. There is no global way to change this settings. To change it for a given application, open or create the configuration file « ~/.config/APPNAMErc » (for Kate: ~/.config/katerc ; for everything related to the desktop: ~/.config/plasmashellrc), and make sure the following section is present.
[PreviewSettings] MaximumRemoteSize=0 MaximumSize=50000000 UseFileThumbnails=true
« MaximumSize » is the maximal size of the files. In this example: 50Mo.
My recommendation: if you want stability and the current version is satisfying for you, do not migrate.
Pour accéder sur Android à une liste de contacts via CardDav (ce que permet par exemple Owncloud), on peut utiliser DAVdroid par exemple. Il y a quelques pièges au niveau des certificats HTTPS.
Le certificat doit être au format CSR, et pas au format PEM (avec ce format, Android ne vous affichera pas le moindre message d’erreur, et le certificat n’apparaîtra mystérieusement pas dans la liste). Pour convertir de PEM à CSR:
openssl x509 -in mon_certificat.pem -outform DER -out mon_certificat.crt
Comme l’indique la FAQ de DAVdroid, le certificat doit avoir l’attribut «CT:TRUE». Premièrement il faut que le certificat soit un CA. J’avais essayé de créer un CA avec cet attribut, puis un certificat-fils avec cet attribut, sans succès (ça semble être un problème d’Android 4.x). J’ai donc créé uniquement un certificat CA pour mon serveur owncloud.
Pour le généré, j’ai créé un fichier de configuration basé sur celui de base «openssl.cnf». Dedans, j’ai modifié la section suivante (comme indiqué dans les commentaires de ce blog):
[ v3_ca ] subjectKeyIdentifier=hash authorityKeyIdentifier=keyid:always,issuer basicConstraints=CA:TRUE
J’ai créé la clé et le certificat d’un trait (et donc sans passer par le mécanisme de requête de certificat):
openssl req -x509 -new -config my_server.cnf -nodes -key private/my_server.key -days 1024 -out certs/my_server.pem
Attention, vous devriez comprendre ce que vous faites quand vous générez des clefs/certificats (quel durée de validité? quel algorithme? etc…).
Les sales coup des diverses sociétés pour rendre la vie de leurs clients difficile me fatiguent. Un exemple récent: pour utiliser son téléphone Samsung, il faut accepter les termes du contrat de licence… affiché dans une petite boîte qui ne fait que 20% de la hauteur de l’écran (4cm sur 10 cm). Si vous faites basculer l’écran en paysage, le texte est à nouveau positionné au début. Bref, tout est fait pour que vous mentiez et cochiez «je comprends et j’accepte».
Samsung, pourquoi méprisez-vous ainsi vos clients?

Je cherchais un téléphone qui tiennent dans la main. Avec cette mode des écrans extra-larges, le choix est réduit. Moi choix c’était porté sur un Sony Xperia Z3 Compact qui avait tout pour plaire, sauf que:
Dur dur. Je ne demande pas la lune pourtant: un téléphone simple et solide, qui tiennent dans la main et permettent d’être root et/ou d’installer des ROM alternatives. En passant du temps à écumer les forums et autre site de Cyanogenmod, je me suis rendu compte que:
Bref, cette situation où les différents acteurs vendent les appareils bien verrouillés m’exaspère. Même les constructeurs qui le voudraient bien doivent respecter la volonté du tout puissant Google: pas de root sur les téléphones estampillés Android. Ou sinon pas d’applications Google, et notamment pas de Play Store, la plus indispensable à mon avis, étant donnés qu’un certain nombre d’applications (comme celle de la SNCF ou celle de votre banque), ne sont publiées que sur Google Play. Une belle position dominante. Monde de merde!
The Wikipedia foundation provides dumps for its projects. Among them, you have the full history of the pages: the dump is a compressed file containing the full text of each revision of each page. As you can guess, as new revisions of the pages are added, the overall space required exponentially grows. So I told myself that contributors should avoid adding tons of very small modifications (each of them adding the content of the full page in the history).
What about the compression of this history? It turns out than lzma (xz, 7zip) performs much better than bzip2. For example, for French Wikivoyage, the 7zip version is 5 times smaller than the bzip2 version. Here are some diagrams with:
For bzip2:
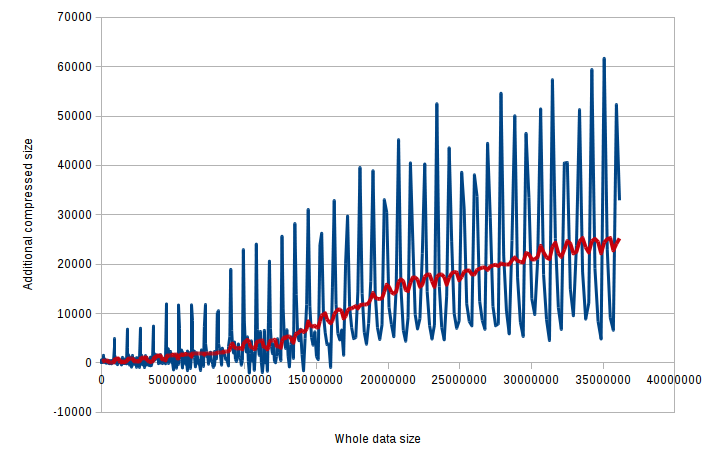 As you can see, the compression rate is decreasing.
As you can see, the compression rate is decreasing.
For lzma: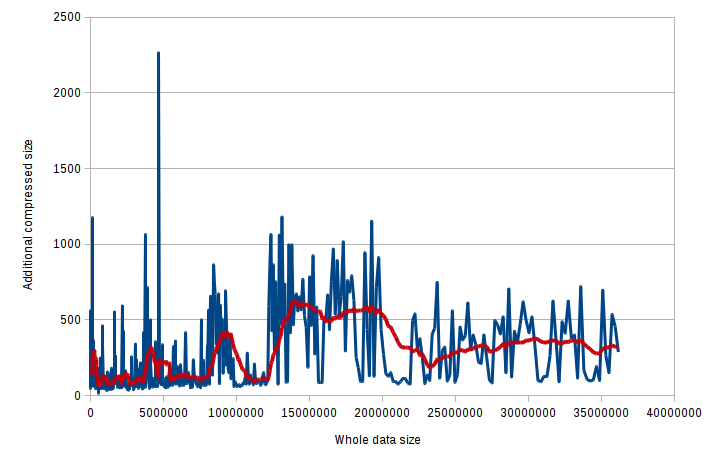 Compression rate over against the full data size for bzip2:
Compression rate over against the full data size for bzip2:
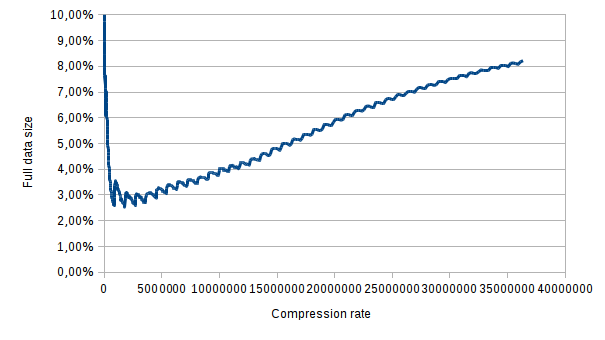 Compression rate over against the full data size for lzma:
Compression rate over against the full data size for lzma:
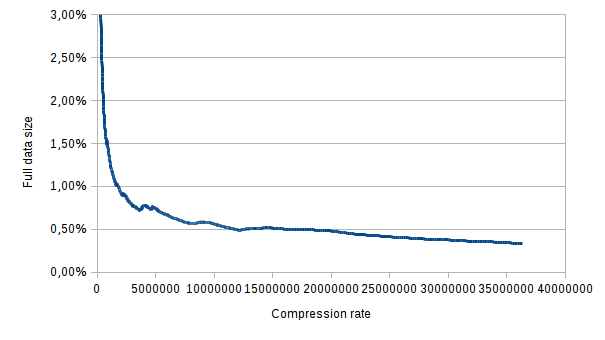 Conclusion: lzma handles much better text that is the very repetitive and large.
Conclusion: lzma handles much better text that is the very repetitive and large.
I expect the bzip2 dumps to grow larger and larger. The French Wikipedia dump is currently 110Go in bz2 and only 15Go in 7z.
Mise à jour de mes paquets Anki de japonais: +91 mots et +8 kanjis, et toujours des corrections et des exemples d’utilisation de mots.
Mise à jour de mes paquets Anki de japonais: +135 mots et +8 kanjis, et toujours des corrections et des exemples d’utilisation de mots.
I thought about porting Anki/Ankidroid to Firefox OS, but I realized that I would be a daunting task (and not just a simple conversion from Python/Java to JavaScript). Why?
First reason: In Firefox OS, there is no native support for Sqlite, the library (and file format) used by Anki. There is a port of Sqlite done using emscripten (a C/C++ to Javascript converter), but it only operates on in-memory databases. So if you want to modify an existing Anki file, you need to load it completely in memory (mine is larger than 70Mo!), work on it, then save it completely in the end. So your modifications will not be saved after a transaction/card review, and working in memory may not fit with cheap phones.
Second reason: In Sqlite, there is an abstraction layer for I/O operations for each OS/family of OS. But it does not seem possible to create a implementation for Firefox OS… because the I/O in Firefox OS are asynchronous (when your read/write is done, it will call a callback function). And refactoring Sqlite in order to convert all the synchronous I/O calls to asynchronous calls seems an Herculean work.
What about IndexedDB? The data model of Anki is quite simple, but IndexedDB does not support joins, so it would have to be emulated with JavaScript code. Also, it will not help importing/exporting an existing Anki file…
Conclusion: From what I saw, I feel quite disappointed by the model adopted by Firefox OS, which only proposes a limited set of system API and seems quite limited for the port of existing libraries. Especially the asynchronous I/O aspect. It seems like this model is great for applications developed with Firefox OS in mind, but if you need to port an existing application… May it will get better (I hope there will be an official SQLite support)…
Let say that I have a table with 20 non-null text columns (32 characters long), 20 non-null integers and a blob (bytea, nullable). When inserting records, what is the overhead of setting the blob? Answer: about no difference up to 80ko. From that it get slower.
Testing details: 2000 records (on 2000 transactions), inserted on 16 threads, each of them having a persistent connection. The DB server is on the same machine (Ubuntu amd64), no particular configuration.
Mise à jour: à partir de Firefox 59, cela se passe comme ça. La procédure ci-dessous concerne les versions antérieures à Firefox 59.
Pour avoir l’interface de Firefox en japonais, on peut bien sûr télécharger la version japonaise. Ou bien on peut installer un «pack de langue». Comme ceci:
Redémarrez votre navigateur. Préparez-vous à être un peu perdu.